
Introduction
[1] Anyone who has interacted with generative models like ChatGPT or Midjourney knows that their responses can sometimes be deeply flawed. Large language models (LLMs) will sometimes confabulate[1] factual errors. They can also respond in manners that are biased, racist, sexist, or explicit.[i] Text-to-image diffusion models can make relatively harmless errors like misspelling image text. They can also be used to generate pornographic images of real people.[ii] While inappropriate or misleading internet content is nothing new, generative models can create an unparalleled volume of such content.
[2] How did we get here? If developers and researchers program these generative models, why is it so difficult to avoid erroneous and harmful responses? With rising distrust of big tech companies, skeptics might conclude that these problems are either the result of sloppy programming or an intentional and malicious purpose. Sci-fi fans might see these problems as evidence that generative models have gained consciousness or have broken free from their developers and are beyond our capability to meaningfully control. Yet neither of these perspectives capture the urgent reality of generative model research: this is a hard problem to solve. Ensuring that a model’s objectives, values, and standards match those of its users is known as the alignment problem.[iii] Our current attempts at alignment have given rise to thorny technical and ethical questions, and most of these remain unsolved.
[3] In this piece, we first outline how generative models operate. We then explore some alignment problems posed by generative models and the methods being used to counteract these problems. Along the way, we will consider the ethical decision-making that takes place as researchers continue to improve on these models. For developers working with generative models, this work points out some of the ethical and moral decisions that are required when aligning a model with the values of an organization and its users. For ethicists considering how generative models ought to be aligned (be it morally, politically, socially, or otherwise), this work delineates why aligning generative models with even simple objectives can be surprisingly problematic, and suggests some open problems where additional research in ethics could be especially helpful.
How Generative Models Work
[4] A generative model is a class of machine learning model that attempts to closely emulate a given distribution of data.[iv] Suppose we have instances from a collected dataset (text, images, videos, etc.) which we call  . We assume that these instances are independently drawn from a global data distribution . For example, with text, this global data distribution might encompass all writing on the internet. While there are many types of generative models, they all share a common objective: approximate a close representation of
. We assume that these instances are independently drawn from a global data distribution . For example, with text, this global data distribution might encompass all writing on the internet. While there are many types of generative models, they all share a common objective: approximate a close representation of  (call it
(call it  ) using only the collected dataset . Let us consider two state-of-the-art generative models: autoregressive models (driving tools ChatGPT[v]) and diffusion models (driving tools like Midjourney[vi]).
) using only the collected dataset . Let us consider two state-of-the-art generative models: autoregressive models (driving tools ChatGPT[v]) and diffusion models (driving tools like Midjourney[vi]).
[5] Autoregressive models rely on statistical dependencies between different parts of a data point. Suppose that it might break a dataset instance  into its substituents
into its substituents ![x=[x_1,x_2,…x_n]](https://learn.elca.org/jle/wp-content/ql-cache/quicklatex.com-e0f9cae65ee46ccb67097e4b704e5497_l3.png "Rendered by QuickLaTeX.com") . These substituents might be pixels of an image or words in a paragraph. Like the maxim “birds of a feather fly together”, we intuitively recognize that substituents can carry complex relationships between one another. For example, an image showing a pair of glasses is also likely to contain eyes. This likelihood could be expressed as
. These substituents might be pixels of an image or words in a paragraph. Like the maxim “birds of a feather fly together”, we intuitively recognize that substituents can carry complex relationships between one another. For example, an image showing a pair of glasses is also likely to contain eyes. This likelihood could be expressed as  , which would be read as “the probability an image contains eyes, given that the image contains glasses”. This is known as a conditional probability. Supposing the image has glasses and eyes, it is also likely to contain a nose, which we could write
, which would be read as “the probability an image contains eyes, given that the image contains glasses”. This is known as a conditional probability. Supposing the image has glasses and eyes, it is also likely to contain a nose, which we could write  . Autoregressive models are trained to estimate the conditional probability of a data component, given other components are assumed to be present or absent. For an autoregressive model trained on text, where the ordering of words and phrases can be correlated, autoregression leads to the common interpretation of an LLM as a next word predictor. For example, if an LLM returns the words “veni vidi vici”, the calculation being performed is approximately:
. Autoregressive models are trained to estimate the conditional probability of a data component, given other components are assumed to be present or absent. For an autoregressive model trained on text, where the ordering of words and phrases can be correlated, autoregression leads to the common interpretation of an LLM as a next word predictor. For example, if an LLM returns the words “veni vidi vici”, the calculation being performed is approximately:
![]()
![]()
For the next word coming after this statement, the conditional probability would require three conditions, then four conditions, and so on. With each added condition, there is a greater computational cost to be paid. One advantage of state-of-the-art LLMs is their ability to approximate probabilities with many conditions quickly and efficiently. When an LLM is fine-tuned on some additional dataset, the implication is that previously learned conditional probabilities are being tweaked so that text generation more closely resembles the fine-tuning dataset distribution rather than the initial training distribution.
[6] Diffusion models take a very different approach to acquiring  . Diffusion models take an input and iteratively destroy it by adding noise. We can think of our noise as a conditional probability
. Diffusion models take an input and iteratively destroy it by adding noise. We can think of our noise as a conditional probability  , creating a noisier version
, creating a noisier version  given
given  . For a given data instance , we create a series:
. For a given data instance , we create a series:
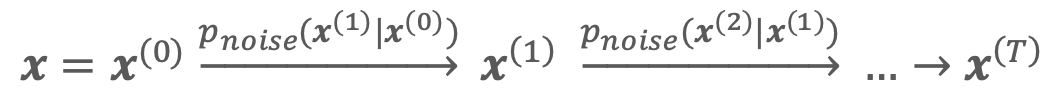
such that after  iterations, the input has been effectively destroyed. Through this process, a diffusion model is trained by learning to subtract the noise we added. We write
iterations, the input has been effectively destroyed. Through this process, a diffusion model is trained by learning to subtract the noise we added. We write  , or a slightly denoised version given , so that from any random starting point we can work our way backwards in a series:
, or a slightly denoised version given , so that from any random starting point we can work our way backwards in a series:
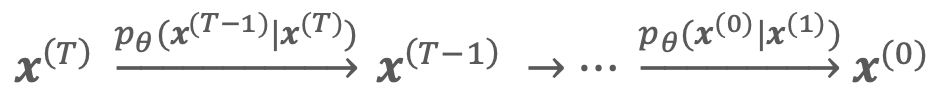
thus allowing us to generate data that appears to originate from the initial training dataset. Rather than requiring random noise as an input, state-of-the-art diffusion models operate using a text-to-image method. Taking text as a model input requires some additional machinery, however the underlying denoising process is effectively the same.
Inherent Limitations of Current Generative Models
[7] From the approaches we detail above, there are several inherent limitations of building generative models that make alignment challenging. A key limitation, which is often pointed out by symbolic AI researchers, is a lack of absolute truths: to a generative model, there is never true epistemic certainty about anything.[vii] Every modelled concept exists on a probabilistic continuum, and a generative model (or any connectionist model for that matter) can only make predictions using the data it was trained on. Even when a trained generative model is making robust predictions, it is inaccurate to say that the model “understands” the concepts that drive its prediction.
[8] Suppose a student is being taught to add two whole numbers. After the teacher explains the concept and works through examples, they administer a test. By asking questions not previously seen, a teacher can assess whether a student understands the concept of addition rather than merely memorizing past question-answer pairs. Once the student understands the concept of addition, the whole numbers being added are irrelevant to that understanding. To a generative model lacking epistemic certainty, the whole numbers being added are always relevant to the correctness of the final answer.[viii] Anything that we might perceive as a form of “understanding” is fleeting, and confabulations are a reality that can be diminished but never fully eliminated. Predicting when and how often confabulations occur is an active area of research.[ix] It seems likely that in the future, generative models will be assessed for certain applications using measures like those employed in other engineering disciplines, such as “probability of failure” and “factor of safety”.
[9] Another inherent limitation of aligning generative models arises from the constraints of the training set. Since probabilities can be more accurately estimated with more observations, it is well understood that the performance of a generative model tends to improve as the training set grows larger.[x] The required size and scope of training sets makes full manual vetting infeasible. Assessing what is allowed or banned in a training set can be thought of as an upstream form of content moderation, and the same ethical questions that surround manual or algorithmic censorship on social media can be approximately transferred to constructing training sets. When training sets are constructed using data scraped from the internet (such as Common Crawl or LAION-400M), it is inevitable that problematic content will be included[xi]. Current text-to-image models can robustly create violent and pornographic imagery only because relevant data is present in the training set. But who should be the authority on what content ought to be censored in a training set?
[10] The ethics of creating properly aligned training sets extends beyond what should or should not be included. Because generative models mimic the underlying probability distribution of the training set, any biases in the training set will be emulated (and sometimes magnified) by the generative model. For example, if a training set contains images of doctors where 80% are white and 20% are non-white, then text-to-image queries for “doctor” will (all else being equal) respond roughly 80% of the time with a white doctor and 20% of the time with a non-white doctor.[xii] While this imbalance may be unethical, and some tools have emerged to help rebalance these likelihoods, how should the right balance be decided? How should diversity, equity and inclusion be incorporated into generative models?
[11] Few would disagree that fair representation is qualitatively important, but at some point, a quantitative decision must be made about what “fairness” means and how to measure it. Failing to quantitatively define “fairness” and correct accordingly, even when doing so is contentious, means that generative models will default to the representations in the training set. Google’s text-to-image model came under fire recently after a ham-fisted approach to address racial and gender representation backfired. Occasionally the model would, without user prompting, create images with historical inaccuracies such as Hispanic men in Nazi uniforms or a black female Pope.[xiii] While Google was singled out for these problematic images, other companies are either trying to make similar corrections for better representation and are encountering the same challenges,[xiv] Others simply are making no serious attempts to correct the issue and are defaulting to the representations of the training set.
[12] Imbalanced content in a training set can exacerbate the harmful stereotypes exhibited by generative models. Some of these stereotypes may be relatively harmless (for example, it is difficult to get a text-to-image model to create a figure of a “nerd with glasses” without glasses appearing anyway), while others are more serious. For a text-to-image model, results for “attractive person” are more likely to be white while results for “poor person” are more likely to be black. Results for “software engineer” are almost entirely male, while results for “housekeeper” are almost entirely female.[xv] There have been similar findings when testing LLMs: doctors are more likely to be given male pronouns, while nurses are more likely to be given female pronouns.[xvi] Suitably aligning models to account for these biases and stereotypes remains an outstanding technical and ethical challenge.
[13] Another open question in generative model alignment is how new information should be incorporated into existing models (referred to as “the knowledge update problem”[xvii]). Suppose a new candidate fills the office of a long-time incumbent politician, how should a generative model be updated to reflect the candidate’s new position? Because the training set contains many references to the long-time incumbent holding the office and few references to the new candidate holding the office, an unchecked generative model will continue to err. Without intervention, generative models have no way to account for information chronology or source reliability, so predictions are formulated based on training set volume more than other factors. Generative models in isolation are a poor substitute for a search engine, as up-to-date accurate information cannot be guaranteed.
[14] The content used for a knowledge update also matters: what if AI-generated responses are reincorporated as training data? Researchers at Amazon AI recently showed that a significant amount of non-English content on the internet has been generated using automated translation tools,[xviii] and one ominous study demonstrated that using training sets that reincorporate AI-generated content led to a decay in generative model performance.[xix] It is possible that performing general knowledge updates using recently scraped internet data may already be infeasible due to possible model decay, so effectively keeping models up to date may become increasingly problematic.
Proposed Alignment Solutions
[15] Now that the inherent problems of aligning and deploying generative models have been established, we will consider some proposed solutions to minimize these problems. For organizations seeking to deploy generative models, utilizing one or more of these strategies can make the potential downsides of generative models more manageable. Apart from fine-tuning, these strategies do not meaningfully alter the underlying generative model. Rather, these strategies use a variety of operations prepended and/or appended to the underlying generative model to increase reliability.
[16] The most low-effort strategy for improving the performance of generative models involves simply adjusting the model input prompt. For a deployed LLM, a lengthy preamble will precede any message passed by the user but will not be visible to the user. A preamble will include what the model is tasked to accomplish, the format(s) the model should use when responding, the tone of responses, and the sorts of prompts it should not respond to. If an LLM is prompted with a specific task and perhaps shown a few completed examples, its performance will be better than if it is not prompted. This is known as zero-shot learning. Zero-shot and few-shot learning is referred to elsewhere as “prompt engineering”, however this name is somewhat misleading. It is well established that prompts are important, and generative models perform best when they are prompted with an objective that is clearly worded and well-defined. Beyond this obvious heuristic, there are few if any provably superior prompting approaches, and obtaining a desired output from a generative model becomes a matter of guess-and-check. Calling zero-shot learning “prompt engineering” is akin to someone who is good at finding answers with a search engine calling themselves an “engineer”. Zero shot learning occurs when no examples are presented in the prompt, or few-shot learning when only a few examples are presented.[xx]
[17] When a task is clearly defined and a separate training set is available, it can be appropriate to slightly modify the generative model based on this separate training set. This approach is known as fine-tuning. For example, an LLM is tasked to respond in a target language not found in the original training set, then the LLM can be fine-tuned on a separate corpus in the target language. However, it is important to note that when a generative model is fine-tuned on a specific task, the model’s performance on other tasks is no longer guaranteed, and should not be trusted for other tasks.[xxi]
[18] Aside from approaches that directly influence the generative model, a wide variety of guardrails have been created to vet the inputs and outputs of generative models without directly interfering with the model generation.[xxii] On the input side, every request is checked before the generative model is invoked. User requests that hit a guardrail (based on containing explicit or violent material, for example) are headed off immediately, and the response is a fixed message. Checking inputs can be as simple as verifying the input does not include any words considered profane, or as complex as training an entirely separate language model to assess whether a user prompt has malicious intent. On the output side, as a generative model response is being created, the response can also be vetted in a similar fashion to the inputs, thus ensuring that both the user input and the model output passed some agreed-upon criteria. If, during generation, the response is no longer within the prescribed guardrails, the response can be randomly regenerated from the beginning.
[19]Another method for curbing model confabulations is retrieval-augmented generation (RAG).[xxiii] Suppose an organization maintains a corpus of trusted materials and would prefer to only utilize those materials for generation. Training a generative model from scratch is often not an option, and fine-tuning for general-purpose use is not always desirable. In contrast, RAG starts by retrieving passages of the trusted corpus that are deemed relevant to a user query, then prompting the generative model using the user query and those retrieved passages for reference. RAG has become an increasingly popular choice for deploying generative models, but it is not foolproof.[xxiv] Responses must still be assessed to ensure that the model did not produce misleading results.
[20] The strategies for better aligning generative models have come a long way. Zero- and few shot learning, guardrails on inputs and outputs, RAG, and other strategies are enabling organizations to properly scope and deploy generative models with the confidence that malicious users should not be able to undermine model generation, responses should align with organizational values, and confabulations should occur rarely. But the field of generative models is moving at a rapid pace. Humanity has yet to solve the alignment problem for generative models. New challenges, solutions, and exploits will arise in the coming months and years, and the tools of today will be subject to the vulnerabilities and misalignments of tomorrow.
Conclusion
[21]There is a lot of confusion about generative models: why they err, when they should or should not be used, and why aligning these models with our values is so difficult. Developers can compound this confusion with hand-wavy explanations and analogies, some of which are taken a bit too literally. In this work, we aim to clarify these perceptions and dispel some misperceptions about generative models. We also point to the inherent limitations of generative models, and where developers could use assistance in thinking through the implications of their decisions when trying to improve on these limitations. Finally, we consider some of the current implementations to better align generative models with human ideals. It is unlikely that generative models will ever be perfectly aligned with what humanity values. Nevertheless, drawing closer to this goal will require the collective work of researchers, developers, ethicists, philosophers, theologians, and many others. There is much to do.
[1] When an LLM makes what humans deem to be a mistake (which is already poorly defined), this is commonly referred to as a “hallucination”. We opt to refer to such a mistake as a “confabulation” for two reasons. First, the term “hallucination” inappropriately anthropomorphizes an LLM, which is disingenuous. Second, the term “hallucination” can be stigmatizing to those with mental disorders such as schizophrenia or dementia.
[i] See, for example, Isabel O. Gallegos, Ryan A. Rossi, Joe Barrow, Md Mehrab Tanjim, Sungchul Kim, Franck Dernoncourt, Tong Yu, Ruiyi Zhang, and Nesreen K. Ahmed. “Bias and fairness in large language models: A survey.” Computational Linguistics (2024): 1-79.
Also, see, Abubakar Abid, Maheen Farooqi, and James Zou. “Persistent anti-muslim bias in large language models.” In Proceedings of the 2021 AAAI/ACM Conference on AI, Ethics, and Society, pp. 298-306. 2021.
[ii] See Ashley Belanger, “Toxic Telegraph group produced X’s X-rated fake AI Taylor swift images, report says.” ArsTechnica, 2024.
Also see, Alexandra Arko, Mark Rasch. “Nudify Me: The Legal Implications of AI-Generated Revenge Porn.” JD Supra, 2023.
[iii] Norbert Wiener, “Some Moral and Technical Consequences of Automation: As machines learn they may develop unforeseen strategies at rates that baffle their programmers.” Science 131, no. 3410 (1960): 1355-1358.
[iv] Andrew Ng and Michael Jordan, “On discriminative vs. generative classifiers: A comparison of logistic regression and naive bayes.” Advances in neural information processing systems 14 (2001).
[v] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Łukasz Kaiser, and Illia Polosukhin. “Attention is all you need.” Advances in neural information processing systems 30 (2017).
[vi] Jasha Sohl-Dickstein, Eric Weiss, Niru Maheswaranathan, and Surya Ganguli. “Deep unsupervised learning using nonequilibrium thermodynamics.” In International conference on machine learning, pp. 2256-2265. PMLR, 2015.
[vii] See Geoffrey E. Hinton, “Preface to the special issue on connectionist symbol processing.” Artificial Intelligence 46, no. 1-2 (1990): 1-4.
[viii] Matteo Muffo, Aldo Cocco, and Enrico Bertino. “Evaluating transformer language models on arithmetic operations using number decomposition.” arXiv preprint arXiv:2304.10977 (2023).
[ix] See Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B. Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. “Scaling laws for neural language models.” arXiv preprint arXiv:2001.08361 (2020).
[x] See, Sebastian Farquhar, Jannik Kossen, Lorenz Kuhn, and Yarin Gal. “Detecting hallucinations in large language models using semantic entropy.” Nature 630, no. 8017 (2024): 625-630.
See also, Fan, Lijie, Kaifeng Chen, Dilip Krishnan, Dina Katabi, Phillip Isola, and Yonglong Tian. “Scaling laws of synthetic images for model training… for now.” In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 7382-7392. 2024.
[xi] See Alexandra Sasha Luccioni and Joseph D. Viviano. “What’s in the box? a preliminary analysis of undesirable content in the common crawl corpus.” arXiv preprint arXiv:2105.02732 (2021).
Also see Abeba Birhane, Vinay Uday Prabhu, and Emmanuel Kahembwe. “Multimodal datasets: misogyny, pornography, and malignant stereotypes.” arXiv preprint arXiv:2110.01963 (2021).
[xii] See Sigal Samuel, “A new AI draws delightful and not-so-delightful images.” Vox (2022).
[xiii] Sarah Shamim, “Why Google’s AI tool was slammed for showing images of people of colour.” Al-Jazeera (2024).
[xiv] Jake Traylor, “No quick fix: How OpenAI’s DALL·E 2 illustrated the challenges of bias in AI.” NBC News (2022).
[xv] Federico Bianchi, Pratyusha Kalluri, Esin Durmus, Faisal Ladhak, Myra Cheng, Debora Nozza, Tatsunori Hashimoto, Dan Jurafsky, James Zou, and Aylin Caliskan. “Easily accessible text-to-image generation amplifies demographic stereotypes at large scale.” In Proceedings of the 2023 ACM Conference on Fairness, Accountability, and Transparency, pp. 1493-1504. 2023.
[xvi] Hadas Kotek, Rikker Dockum, and David Sun. “Gender bias and stereotypes in large language models.” In Proceedings of the ACM collective intelligence conference, pp. 12-24. 2023.
[xvii] Shankar Padmanabhan, Yasumasa Onoe, Michael Zhang, Greg Durrett, and Eunsol Choi. “Propagating knowledge updates to lms through distillation.” Advances in Neural Information Processing Systems 36 (2024).
[xviii] Brian Thompson,, Mehak Preet Dhaliwal, Peter Frisch, Tobias Domhan, and Marcello Federico. “A Shocking Amount of the Web is Machine Translated: Insights from Multi-Way Parallelism.” arXiv preprint arXiv:2401.05749 (2024).
[xix] Ilia Shumailov, Zakhar Shumaylov, Yiren Zhao, Yarin Gal, Nicolas Papernot, and Ross Anderson. “The curse of recursion: Training on generated data makes models forget.” arXiv preprint arXiv:2305.17493 (2023).
[xx] Ming-Wei Chang, Lev-Arie Ratinov, Dan Roth, and Vivek Srikumar. “Importance of Semantic Representation: Dataless Classification.” In Aaai, vol. 2, pp. 830-835. 2008.
[xxi] See Jingfeng Yang, Hongye Jin, Ruixiang Tang, Xiaotian Han, Qizhang Feng, Haoming Jiang, Shaochen Zhong, Bing Yin, and Xia Hu. “Harnessing the power of llms in practice: A survey on chatgpt and beyond.” ACM Transactions on Knowledge Discovery from Data 18, no. 6 (2024): 1-32.
See also, Yupeng Chang, Xu Wang, Jindong Wang, Yuan Wu, Linyi Yang, Kaijie Zhu, Hao Chen et al. “A survey on evaluation of large language models.” ACM Transactions on Intelligent Systems and Technology 15, no. 3 (2024): 1-45.
[xxii] Traian Rebedea, Razvan Dinu, Makesh Sreedhar, Christopher Parisien, and Jonathan Cohen. “Nemo guardrails: A toolkit for controllable and safe llm applications with programmable rails.” arXiv preprint arXiv:2310.10501 (2023).
[xxiii] Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler et al. “Retrieval-augmented generation for knowledge-intensive nlp tasks.” Advances in Neural Information Processing Systems 33 (2020): 9459-9474.
[xxiv] See Zhen Tan, Chengshuai Zhao, Raha Moraffah, Yifan Li, Song Wang, Jundong Li, Tianlong Chen, and Huan Liu. “” Glue pizza and eat rocks”–Exploiting Vulnerabilities in Retrieval-Augmented Generative Models.” arXiv preprint arXiv:2406.19417 (2024).

Marcus Schwarting is a PhD candidate in computer science at the University of Chicago, where his research focuses on applying machine learning to important challenges in computational chemistry, materials science, and quantum mechanics. Marcus graduated from the University of Louisville in 2018 with degrees in mathematics and chemical engineering. After four years at the National Renewable Energy Laboratory and Argonne National Laboratory, he began his PhD in 2020 under Dr. Ian Foster. Marcus is a senior editor of AI and Faith and a contributing member of the Partnership for Applied Biblical Natural Language Processing.